
The challenge
The company wanted to develop a standardized daily satisfaction survey process for Net Promoter Score (NPS). However, the “relational” Net Promoter Score (rNPS) was outsourced and was not flexible enough for the business. The expected monthly survey response volumes were not being achieved. Additionally, the processes of quarantine and blacklisting did not yield the expected results.
To meet the diverse needs of different data sources, the solution should cater to both “transactional” NPS (tNPS) and “product” NPS (pNPS). Stratified sampling becomes essential for rNPS and pNPS.
Moreover, a minimum of seven different touch-points is required for tNPS. To optimize data collection, the database must include valid email addresses and phone numbers, ensuring contactability and minimizing waste. For the survey links, a third-party (Medallia) will handle their management, streamlining the process and enhancing overall efficiency.
Why AWS
BTC successfully integrated all data sources and table generations into the AWS environment, creating a centralized data lake for querying and analysis by the analytics team. The most straightforward solution for building a Standardized Daily Survey Process for NPS was found in AWS’s versatile tool suite. Leveraging Strata’s expertise in AWS, a streamlined data pipeline was established, efficiently handling new data, preprocessing, and generating targeted client samples.
In sum, the combination of BTC’s vision and AWS’s prowess, coupled with Strata’s expertise, led to a remarkable solution that empowered the organization’s data-driven initiatives.
Why the Customer Chose the Partner
In a prior project, Strata collaborated with BTC to develop an entire Data Lake on AWS, and also created processes to map various data sources, establish mechanisms for uploading data, verify consistencies, and build analytical tables within the AWS environment. The successful implementation of this AWS-based solution provided a solid foundation for our expertise in handling the current model requested.
The selection of Strata as the preferred partner for this project was well-founded. Our experience in developing comprehensive solutions on AWS in the telecommunications sector and beyond, made us the ideal choice for the task at hand. We bring a wealth of knowledge and proficiency, ensuring the delivery of exceptional results in this project as well.
Partner Solution
The proposed solution is based on the extraction of information from the DNA of Postpaid, Fixed, and Prepaid B2C clients for the creation of a comprehensive dataset.
The conditions for dataset creation were different for tNPS, rNPS, and pNPS. While tNPS is created based on the actions of the clients over the previous day (7 days ago), rNPS and pNPS are not based on the actions of the clients; all DNA active clients are included.
This solution adheres to a daily priority order, where clients are initially reserved for high-priority touchpoints such as t-onboarding, t-install, etc. Subsequently, rNPS is addressed, followed by lower-priority touchpoints like t-change, etc. Finally, pNPS is considered.
The solution is designed with a multi-stage approach. Here’s the sequence in which it was executed:
1. Sampling Business Intelligence Filters: In this process, the dataset created for all NPS process is taken, and the corresponding filters are applied based on the database of quarantined clients and the black list. The output of this process is the “Sample Space” database. In this step, only customers who have at least one way to contact them, by email and/or cell phone, are selected.
2.a. For tNPS: Sampling Customer Care Filters: Starting from the Sample Space file, customers are further filtered, and only a selected group is kept, depending on the different eligibility criteria for each touchpoint. The result of this stage is a database containing potential customers to survey.
2.b For rNPS and pNPS: Sampling Customer Care Filters: Building upon the results of the previous step, we proceed to filter customers, retaining only a specific subset. The client eligibility criteria are determined based on the desired number of customers to be identified by the end of the month. These criteria will be developed in accordance with the “Autoscaling” process, which is described later.
3. The selected customers from the different processes (rNPS, tNPS, and pNPS) are combined, and relevant variables of interest are added. Subsequently, this file is sent to Medallia to conduct the surveys.
For rNPS and pNPS, a process called Autoscaling was created to automatically adjust the number of surveys that will be sent for the rest of the month based on the number of surveys that were answered in the preceding days.
The Autoscaling process is defined by setting a fixed number of responses to be obtained per product in the month, with the goal of achieving that target by the end of the month. Surveys are sent from the first business day of the month; however, for obvious reasons, not all customers will respond to the surveys. This is where the autoscaling process comes into play, as it works to obtain the required responses by the end of the month by determining day by day how many surveys must be sent.
HL Architecture
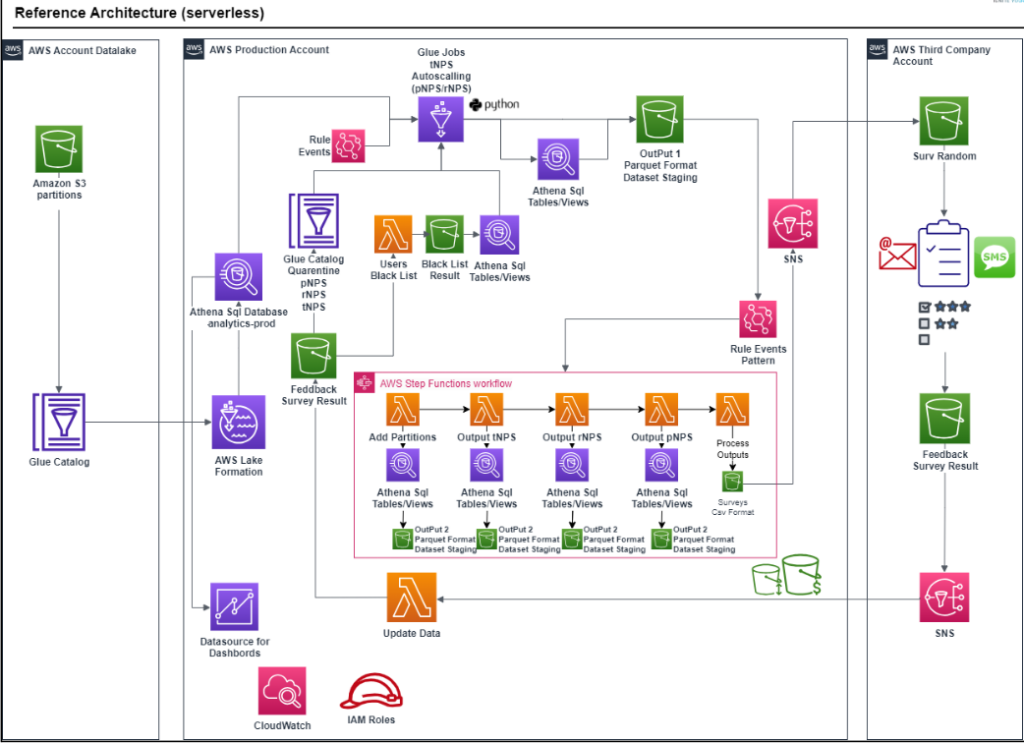
A distributed data processing system was required due to the large daily volume of data received, and AWS Glue for Apache Spark was the service that best suited the customer’s requirements.
The data sources mentioned above are processed through a scheduled event, and an execution of an AWS Glue ETL Job takes place to apply filters and carefully clean the data, discarding incomplete or evidently erroneous data. Additionally, the filters of the clients in the blacklist and quarantine (in that order) are applied. The blacklist database is generated by Amazon Athena from the received feedback surveys and is updated daily.
The Sample Frame, which is the first “clean” dataset in the staging area, is generated by the AWS Glue Job Process, serving as input for the next Sampling CC Filters activity. Following the defined order of priority, the generated dataset is used as a master sample, and high priority touchpoints, rNPS, low priority touchpoints, and pNPS are sequentially executed. Both the pNPS and rNPS processes are subject to Autoscaling. The Autoscaling process, along with the generation of outputs for tNPs, pNPS, and rNPS, is carried out using AWS Glue for Apache Spark Jobs, connected with the AWS Glue Data Catalog, and storing the partitioned data in the project bucket. The Autoscaling process, similar to the blacklist, is fed back from the received feedback, adjusting the number of users to contact based on a simple mathematical algorithm.
Once the creation of the Dataset to be contacted is completed, an AWS Step Functions state machine is triggered to orchestrate the subsequent process, which is responsible for completing each of the surveys with additional information, mainly using the AWS Lambda service and the Amazon Athena database. Upon completion, output files in CSV format are generated and stored in a specific Amazon S3 bucket with an associated lifecycle policy. An event is triggered via Amazon Simple Notification Service (SNS) by this script. These files are sent daily, in addition to being stored in the AWS Glue Data Catalog.
Once the NPS process is completed by the company in charge of conducting the surveys, the resulting CSV is published in a specific Amazon S3 bucket. The associated Amazon SNS topic executes an AWS Lambda function that updates the survey results and simultaneously generates a file in the AWS Glue Data Catalog to add the information to the DNA. This serves as feedback for the full cycle and will provide the dataset that Amazon Quicksight will consume in the future.
Results and Benefits
The implemented solution is completely automatic, when new information is available it triggers the entire process, generating an output in approximately 45 minutes of processing. The solution was designed to be flexible, allowing for potential modifications in the order of executions and priorities in the future without significant inconvenience.
Next Steps
The following steps are aimed at generating a near real-time orchestration similar to the one involving shipments three times a day for the touchpoints: t-Installs (installations), t-Install self-service (installations made by the client), and t-Truck rolls (repairs). This will be achieved by directly utilizing the real-time updates of Service Orders (SO).